Build
My name is Christian Hunt, I am the great grandson of Dr Ferdinand “Fred” Callsen. I came into possession of these letters from my mother Carole Hunt, Dr. Callsen’s granddaughter. Not only was I thrilled to have a piece of family history that spoke directly to a time period, but as a WW1 collector and enthusiast, these letters were particularly special. I immediately felt they needed a voice, figuratively and literally, beyond the archival sleeves I gave them.
I work as a Data Science Director for a large organization. More specifically I lead teams that prepare data for data science solutions (Data Analytics Engineers) and that put models into production (Machine Learning Engineers). As this field evolves, we are seeing the strong influence of cloud technology, Dev/Ops (MLOps) and Machine Learning Tool sets. I decided it would be an interesting project to see how many of these ‘developer as data scientist’ tools I could integrate in bringing Lt Callen’s WW1 letters to life. Keep in mind that I no longer develop code as my day job, so some of my solutions may be a little rough around the edges. This system was built on Amazon Web Services (AWS) and my goal was to be as ‘tool centric’ as possible.
I will admit to a bit of AWS architectural laziness for this project. AWS best practice would have called for an SNS Fanout from the original download of the letters. Since this was a learn/do project, using the Create Object events from the S3 buckets (storage) allowed more freedom to build the project sequentially. I also did not make any attempts to use Terraform or other automation in the creation but stuck to the Control Pannel. The system is hugely overdesigned for the task, automating the entire process from letter upload, transformation to placement on Fredswar.com. This was part of the fun.
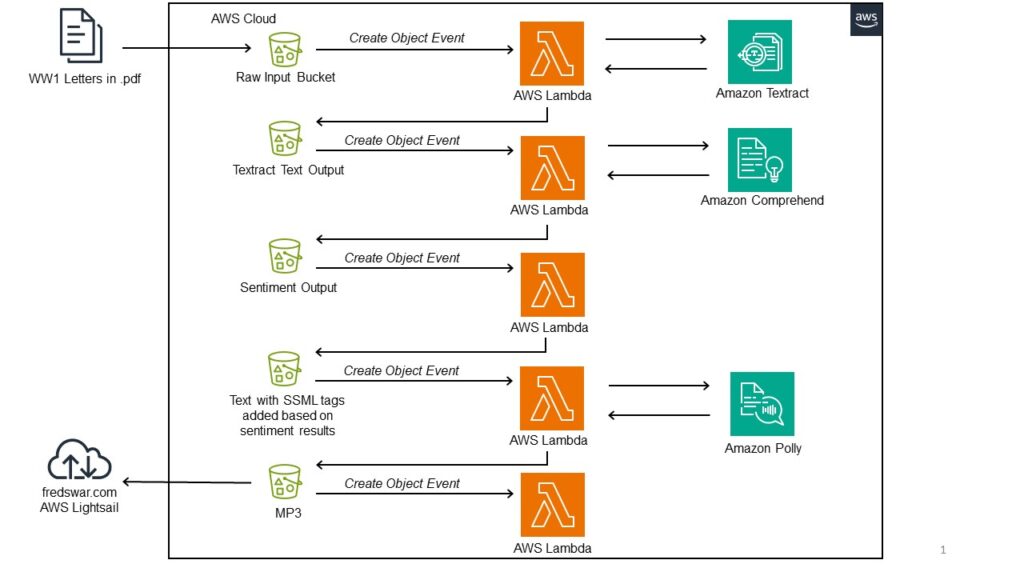
The system starts with the upload to an AWS S3 bucket, individually or in mass, of Fred Callsen’s letters from WW1 in .pdf format. An AWS Lambda (compute) function detects the upload (Create Object) and passes the .pdf to AWS Textract. Textract extracts the text from the cursive letters. Another Lambda is triggered by that event and passes the text to AWS Comprehend. Comprehend scans the file and decides whether it is “Positive”, “Negative”, “Neutral” or “Mixed” in its sentiment. Yet another Lambda is triggered by the return of this data and combines the Comprehend sentiment back with the original text, then transforms the sentiment to SSML tags, mostly to change the voice (vocal tract length, prosody pitch and breath) to match a “Positive”, “Negative” or “Neutral” tone. This SSML tagged document is then passed to AWS Polly from another Lambda function, which produces an MP3 file. This file is then loaded to Fredswar.com from an S3 bucket. Fredswar.com is a WordPress site hosted on AWS Lightsail.
Notes on the Machine Learning Tools Used
The Machine Learning Tools, AWS Comprehend and Textract were easy to interact with. Most of the work was in the Lambda function, getting them to interact with tools automatically and getting data to and from the tools. AWS Polly was another issue. Equally easy to interact with, however language SSML tags are a bit or an art form I have yet to completely master.
Not being a web developer, I was looking for an easy way to host the site. I would highly recommend AWS Lightsail. I was able to set up the infrastructure for the site in just a few minutes. Figuring out how to make WordPress work and look good took a few days of very part time work. Although much of this was due to artistic endeavors, not technical complexity.
An honorable mention should also go to Chat GPT. The initial version for some of the Lambda functions started off as queries to Chat GPT. However, anyone who thinks Chat GPT is the death of programming is very mistaken. Chat GPT provided good answers only when you know quite a bit already about what you are asking and can understand the results. Very specific, carefully worded questions, providing strong details, were the only queries that produced decent results.
Results:
Overall Processing Time: To accommodate the AWS Polly size limit, I had to approximate the 3,000 character limit on intake, so 28 letters became 37 texts segments. Overall processing time for the 37 text segments was under 2 minutes. There were no errors in processing, except one which was beyond the 3,000 character limit. Also, no Lambda function came close to maxing out on computational time. Processing had a bit of linear feel, and could have been faster, probably produced by my ‘Create Object’ dependent architecture decision.
Accuracy of the Text: Considering the age, fade, cursive writing, abbreviations, dated terminology used, Textract did a pretty good job creating the text. I would estimate that nearly 70 – 80% of the text was created correctly. Unfortunately, I did not have time to do direct word counts to produce some type of ‘ground truth’ for a more accurate comparison. I used my reading of the letter compared with the Textract output. A couple letters were really bad, one or two were excellent with perhaps over 90% correctly recognized. Curiously clarity of the writing to the human eye made little difference in the accuracy, small changes in the writing style made more differences. Some areas Textract did poorly at were interpreting changes in writing direction, headers and lists. Paper was hard to come by during WW1 with war rationing, so Fred Callsen used any part of the paper he could, including margins. Textract confused this often and require manual ordering to fix, mostly image cut and paste prior to input. On the other end, Textract was confused by headings and lists. This often required a manual fix after Textract.
All considering, this was an impressive result on a difficult set of documents.
Accuracy of the Sentiment: Again, I have no ‘ground truth’ to compare the results to, other than my opinion of the letter’s content. Army life in 1917-1918 was hard, even on the ‘island paradise’ Fred spent much of his time in. I would estimate that out of the 37 texts, 9 are positive, 6 are negative and 22 are neutral. AWS Comprehend predicted 11 are positive, 5 are negative and 21 neutral (1 mixed was added to neutral).
Confusion Matrix
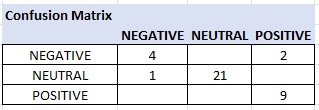
Sums equaled: True Positive 34, False Negative 3, False Positive 3 and True Negative 71.
Precision and Recall are both around .91 with these results (False Negative and False positives are both 3). To dampen your enthusiasm a little on this result, Comprehend also had some epic fails. For example, a description of allies being ‘crucified’ was rated as a positive text. Also Fred Callsen left little to the imagination on whether he was having a good or bad day. Interestingly, even after cleaning up the text for AWS Polly, the Comprehend scores were similar. This would indicate that AWS Comprehend employs more of a ‘bag of words’ approach, perhaps with common misspellings, and is not concerned about words in context.
Some Artistic Notes:
The website is designed for family members to read and listen to Fred’s letters. It would be tempting, for the geek in me, to leave the version created by automation out there. However even 90% correct AWS Textract recognition still makes for a rough spoken word when fed to AWS Polly. I needed to clean it up. Post this process, I added more pauses (break tags) and sentence recognitions (s tags) and cleaned up some things that Textract did not do well, like lists and abbreviations. Additionally, although the site is set up to place .mp3 files automatically, I replaced those .mp3 with .mp4 video files, created with Microsoft Clipchamp, that display the letter and items enclosed in the envelopes.
For those of you who appreciate the Data Science and AWS aspects of this site, my apologies for the departure from the purity of the solution!
Images:
Most of the images used on this site were created from photographs, letters and memorabilia in my own collection. There are a few items that I have borrowed with permission from other websites and forums in the public sphere on similar topics. Particularly from one very good collection on https://www.usmilitariaforum.com/forums/ “Pineapple Army Archive, CAR” to which I have added attribution with each photo.
Artillery at Fort DeRussy around 1917, Territory of Hawaii. From my collection.
